Kunstig intelligens og maskinlæring innen cybersikkerhet
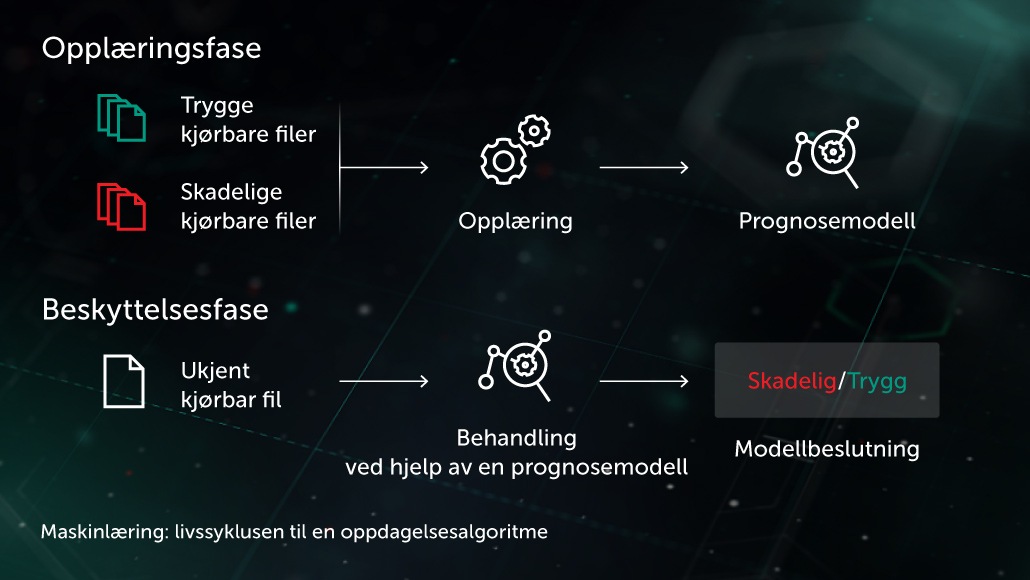
Arthur Samuel, en pioner innen kunstig intelligens, beskrev KI som en samling metoder og teknologier som "gir datamaskiner evnen til å lære uten konkret programmering". I et spesielt tilfelle av overvåket læring for antiskadevare, kan oppgaven formuleres slik: gitt et sett av objektegenskaper \(X\) og tilsvarende objektmerking \(Y \) som innmating, lag en modell som vil gi korrekte merker \(Y' \) for tidligere usette testobjekter \(X' \). \(X \) kan være egenskaper som representerer filinnhold eller atferd (filstatistikk, liste over brukte API-egenskaper osv.) og merker \( Y \) kan ganske enkelt være "skadevare" eller "godartet" (i mer komplekse saker kan vi være interesserte i en fin klassifikasjon som virus, trojan-nedlaster, annonsevirus osv.) Ved læring uten tilsyn er vi mer interessert i å avsløre skjulte datastrukturer, for eksempel å finne grupper med lignende objekter eller egenskaper med sterk korrelasjon.
Kasperskys neste generasjons flerlagsbeskyttelse bruker KI-metoder , f.eks. ML, i stort omfang gjennom hele oppdagelsesprosessen — fra skalerbare grupperingsmetoder brukt til å forhåndsbehandle innkommende filstrømmer, til robuste og kompakte nevrale nettverksmodeller for atferdsregistrering som fungerer direkte på brukerens maskin. Disse teknologiene er utformet for å behandle flere viktige krav for bruk av cybersikkerhet i den virkelige verden, inkludert en ekstremt lav mengde falske alarmer, modellenes tolkbarhet og motstandsdyktighet mot fiender.
La oss ta for oss noen av de viktigste ML-baserte teknologiene som brukes i Kasperskys endepunktsprodukter:
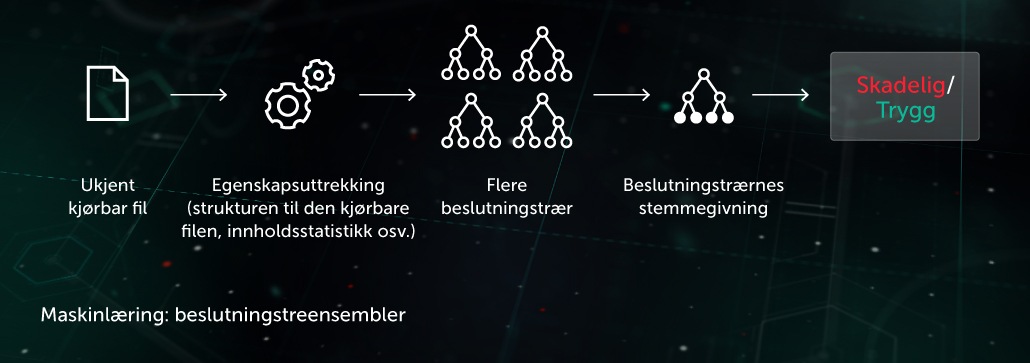
Beslutningstreensemble
Med denne metoden er prognosemodellen utformet som et sett med beslutningstrær (f.eks. trær av typen "random forest" eller "gradient boosting"). Hver node på treet som ikke er en bladnode, inneholder spørsmål om egenskapene til en fil, mens bladnodene inneholder den endelige beslutningen til treet om objektet. I løpet av testfasen går modellen gjennom treet ved å svare på spørsmålene i nodene med de korresponderende egenskapene til objektet som er under vurdering. I det endelige stadiet blir beslutningene til flere trær gjennomsnittsberegnet på en algoritmespesifikk måte for å treffe en endelig beslutning om objektet.
Modellen er fordelaktig for stadiet for proaktiv førutførelsesbeskyttelse på endepunktområdet. Et av programmene våre innen denne teknologien er Cloud ML for Android, som brukes til å oppdage trusler mot mobilenheter.
"Similarity hashing" ("Locality-sensitive hashing")
Tidligere ble hasher brukt til å skape skadevare-"fotavtrykk" følsomme for alle små endringer i en fil. Denne svakheten ble utnyttet av dem som utviklet skadelig programvare, med forvirringsteknikker som polymorfisme på serversiden: Mindre endringer i den skadelige programvaren gjorde at den ikke ble oppdaget. Likhetshashing (eller "locality-sensitive hashing") er en KI-metode for å oppdage skadelige filer som ligner. Systemet gjør dette ved å trekke ut filegenskaper og bruke læring basert på ortogonal projeksjon for å velge de viktigste egenskapene. Deretter brukes ML-basert kompresjon, slik at verdivektorene til lignende egenskaper forvandles til lignende eller identiske mønstre. Denne metoden gir god generalisering og reduserer basen med oppdagelsesregistreringer betydelig, siden én registrering nå kan oppdage hele familien med polymorf skadelig programvare.
Modellen er fordelaktig for stadiet for proaktiv førutførelsesbeskyttelse på endepunktområdet. Den brukes i SH-oppdagelsessystemet vårt.

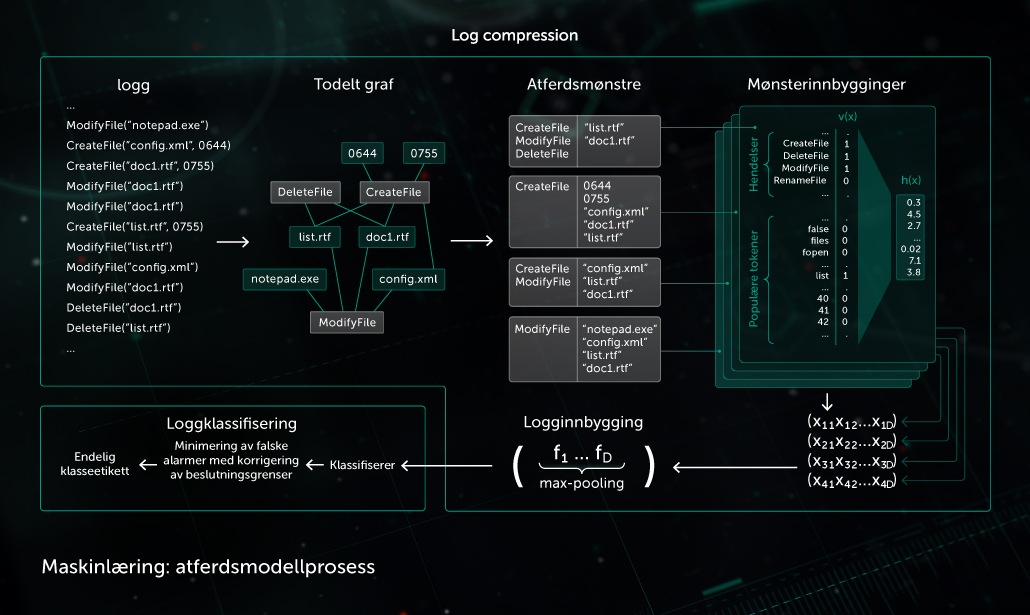
Atferdsmodell
En overvåkingskomponent lager en atferdslogg — rekken med systemhendelser som oppstod da prosessen ble utført, sammen med korresponderende argumenter. For å oppdage skadelig aktivitet i observerte loggdata komprimerer modellen vår rekken med hendelser til et sett med binære vektorer og lærer opp det dype nevrale nettverket til å skille mellom rene og skadelige logger.
Objektklassifiseringen som utføres av atferdsmodellen, brukes av både statiske og dynamiske oppdagelsesmoduler i Kaspersky-produkter på endepunktsiden.
KI spiller en like viktig rolle i å bygge god infrastruktur for skadevarebehandling i laboratoriet. Kaspersky bruker den til følgende infrastrukturformål:
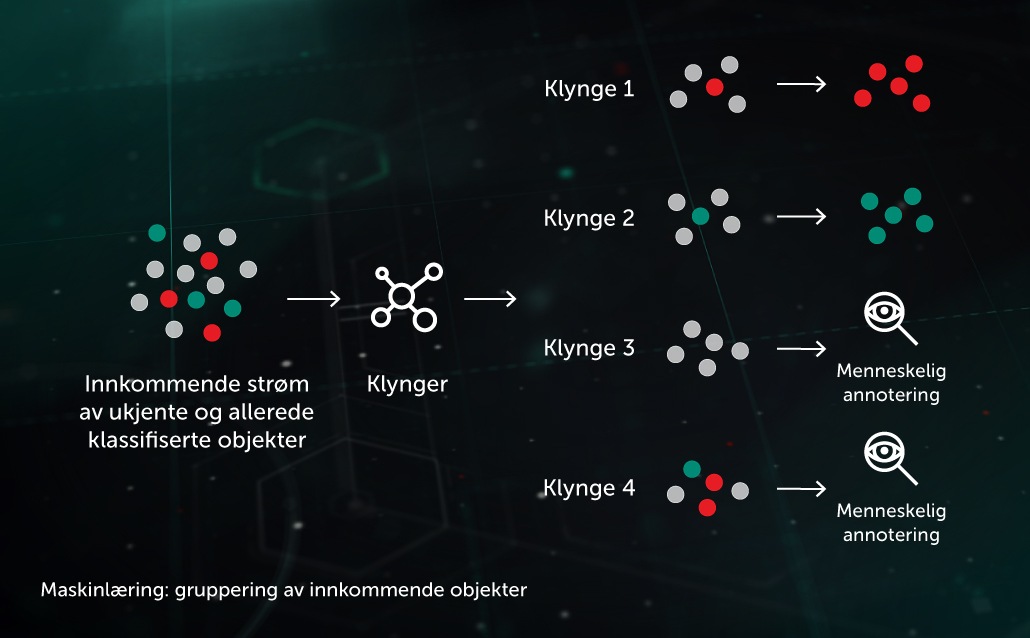
Gruppering av innkommende strømmer
Med ML-baserte grupperingsalgoritmer kan vi effektivt dele opp de store mengdene med ukjente filer som kommer til infrastrukturen vår, i et rimelig antall klynger. Noen av disse kan behandles automatisk basert på at den inneholder et objekt som allerede er merket.
Modeller for storskalaklassifisering
Noen av de kraftigste klassifiseringsmodellene (f.eks. en enorm "random decision forest") krever store mengder ressurser (prosessortid, minne) og dyre egenskapsuttrekkere (f.eks. kan behandling via sandkasse være nødvendig for detaljerte atferdslogger). Derfor er det mer effektivt å oppbevare og kjøre modellene på et laboratorium og deretter sammenfatte kunnskapen som tilegnes av slike modeller, ved å lære opp en lett klassifiseringsmodell i beslutningene som treffes av den større modellen.
Sikkerhet ved bruk av ML-aspektene til KI
Når de slippes ut av laboratoriet til den virkelige verden, kan ML-algoritmer være sårbare overfor mange typer angrep som er utformet for å tvinge KI-systemer til å gjøre feil med vilje. En angriper kan forgifte et opplæringsdatasett eller utføre omvendt utvikling av modellens kode. Hackere kan også bruke "rå kraft" på ML-modeller ved hjelp av spesialutviklede "fiendtlige KI-systemer" for å opprette mange angrepseksemplarer samtidig og sende dem mot beskyttelsesløsningen eller uthentede ML-modell til det oppdages et svakt punkt i modellen. Slike angrep på KI-baserte beskyttelsessystemer mot skadelig programvare kan forårsake enorme skader: En feilidentifisert trojaner innebærer millioner av infiserte enheter og økonomiske tap på flere millioner dollar.
På grunn av dette skal man vurdere noen viktige punkter når man bruker KI i sikkerhetssystemer:
- Sikkerhetsleverandøren må forstå og oppfylle viktige krav for at KI skal fungere i den virkelige, potensielt farlige, verden — krav som omfatter motstandsdyktighet overfor potensielle angripere. ML/KI-spesifikke sikkerhetskontroller og "red-teaming" skal være nøkkelkomponenter i utvikling av sikkerhetssystemer som bruker KI-aspekter.
- Når du vurderer sikkerheten til en løsning som bruker KI-elementer, spør i hvilken grad løsningen avhenger av data og arkitektur fra tredjeparter, siden mange angrep er basert på innmating fra tredjeparter (trusseletterretning, offentlige datasett, forhåndsopplærte og outsourcede KI-modeller).
- ML/KI -metoder skal ikke anses som en løsning på alt – de må være del av en sikkerhetstilnærming i flere lag der utfyllende beskyttelsesteknologi og menneskelig ekspertise samarbeider og passer på hverandre.
Det er viktig å vite at selv om Kaspersky har omfattende erfaring innen effektiv bruk av KI-aspekter som ML og dets dyplæring-undersett i sine datasikkerhetsløsninger, er ikke disse teknologiene ekte KI eller kunstig generell intelligens (KGI). Det er ennå langt igjen til maskiner kan fungere uavhengig og utføre de fleste oppgavene helt selvstendig. Til da vil nesten ethvert aspekt av KI innen datasikkerhet trenge veiledning og ekspertise fra menneskelig fagpersonell for å utvikle og raffinere systemene og utvikle kapasiteten deres med tida.
Hvis du vil ha en mer detaljert oversikt over populære angrep mot ML/KI-algoritmer og beskyttelsesmetoder mot disse truslene, kan du se det tekniske dokumentet "AI under Attack: How to Secure Artificial Intelligence in Security System".




